“Nobody phrases it this way, but I think that artificial intelligence is almost a humanities discipline. It’s really an attempt to understand human intelligence and human cognition.” —Sebastian Thrun
機器學習是已經知道特徵,所以函數的形狀是固定的(例如:如果是一次函數就是線性的,二次則為拋物線),透過訓練去改變權重也只是改變這個函數的位移、斜率等等…。
但是深度學習是連函數的特徵都不知道,也就是不知道函數”應該”要長怎樣,這時候一個天才的想法就出現了:
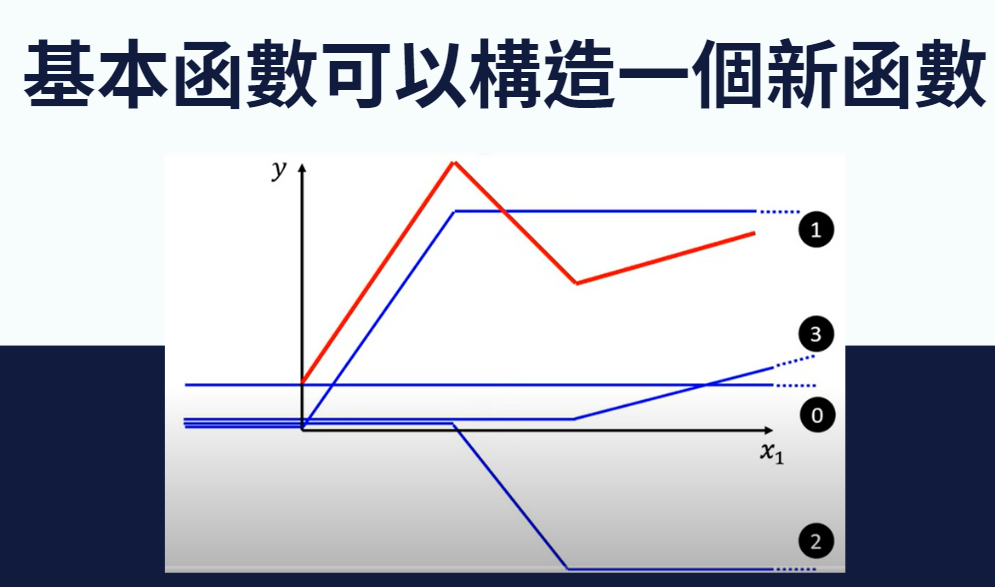
(來源:【機器學習2021】Hung-yi Lee 預測本頻道觀看人數 (下) - 深度學習基本概念簡介)
藍色的函數是基本函數,透過這四個基本函數去組合出紅色函數,也就是說,我們可以製造很多很多的基本函數,這些基本函數可以組合成各式各樣千變萬化的函數。
而基本函數又稱為”神經元”,這些基本函數需要從一個最初的模板函數去變化而來(例如調整權重去伸縮、位移),一個常見的模板函數就是Sigmoid:
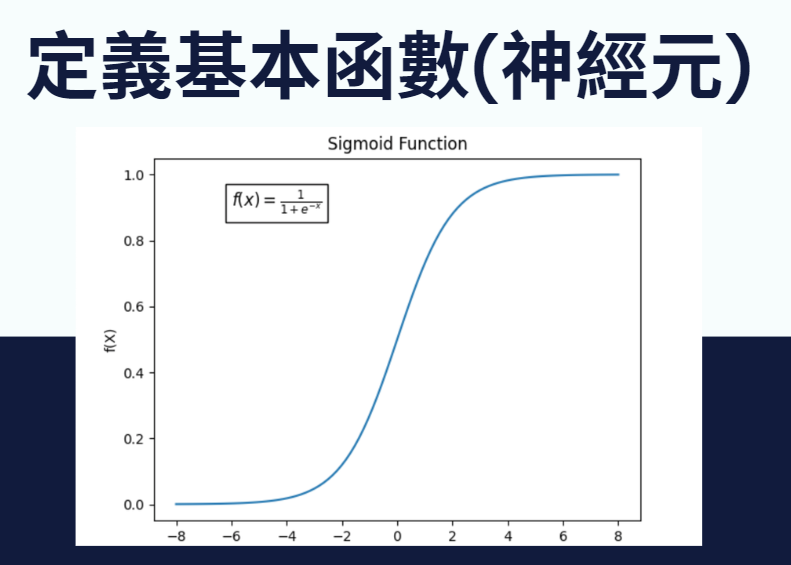
接下來讓我們對這個函數新增一些權重,讓我們能對它其進行各式各樣的變化:
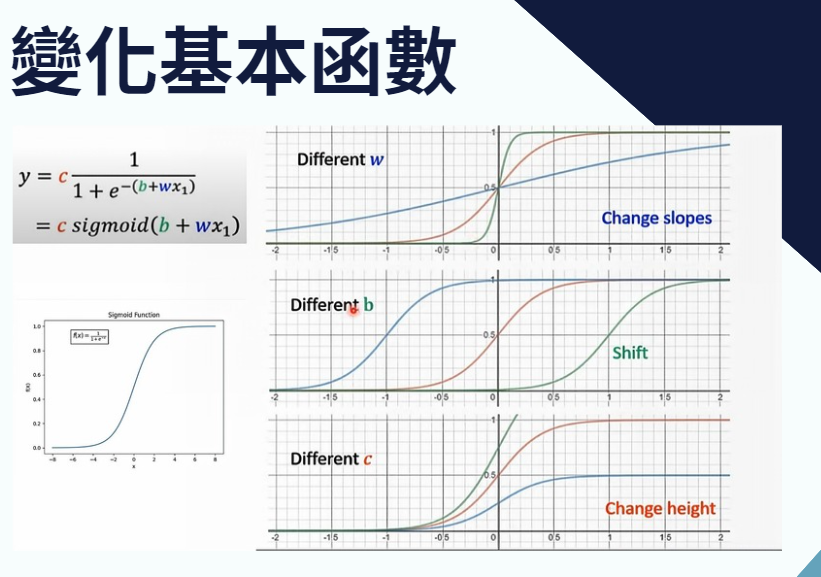
(來源:【機器學習2021】Hung-yi Lee 預測本頻道觀看人數 (下) - 深度學習基本概念簡介)
看到這個架構圖,你就了解為什麼深度學習又稱作類似神經網路了:
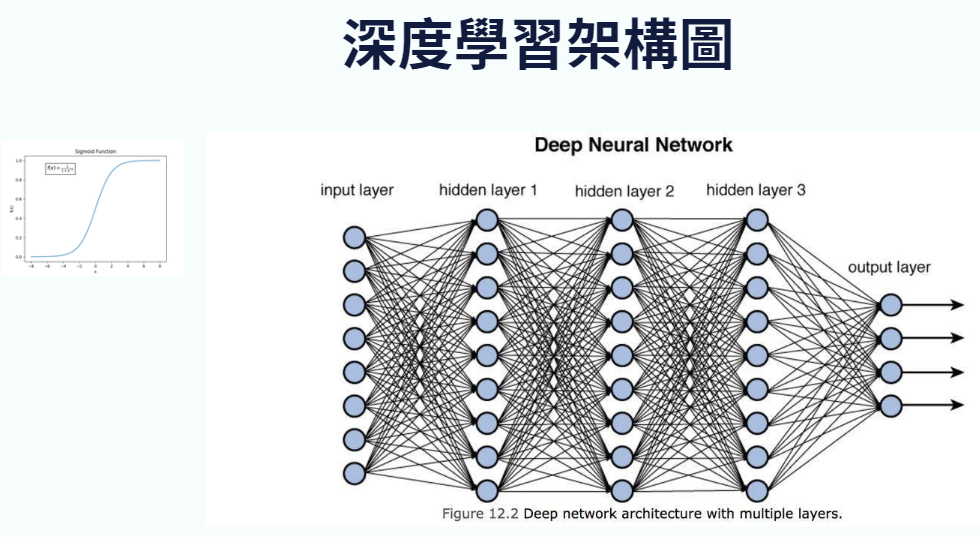
這些藍色的點點,每一個都是一個神經元,也就是一個基本函數,所以我們會有很多很多的基本函數所組成的一個函數。
那這邊密密麻麻的線是什麼意思?這代表每個基本函數會對下一層的基本函數做關聯,可能會是前一個基本函數帶入所得到的輸出,會變成下一層的其中一個輸入,然後不斷進行下去。
剛開始的函數可能是一個爛函數,我們需要做對比與更新,一樣是去找Loss,進行前面提到的greadient descent。(想要繼續深入的可以參考3Blue1Brown的介紹)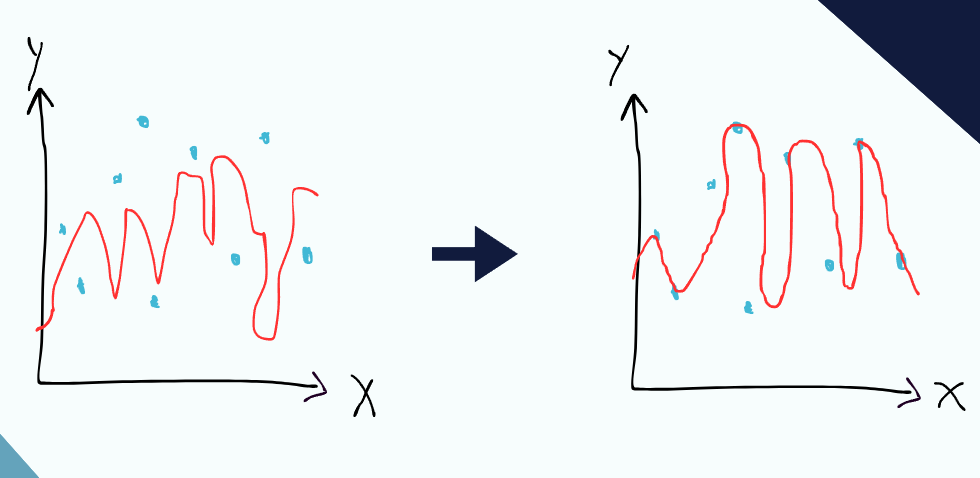
舉個例子:
假設我想要分辨一張圖片是不是一隻狗,訓練資料是十張黑色的狗,原本的那些神經元所找出的特徵可能只有眼睛、耳朵、尾巴。
這時候你又加了很多神經元,的確最後訓練出來的函數,可以在這十張圖片有很高的正確率,但是我們的最終目的是要預測沒看過的圖片,如果這些多的神經元去把黑色當成了一個特徵,要是接下來要預測的圖片是一張棕色的狗,由於它不符合黑色的這個特徵,所以可能就會分辨錯誤。
這就是為什麼不是一直把模型變得複雜就好,而是要依照經驗和理解去找出最適合的模型架構!


 iThome鐵人賽
iThome鐵人賽